Databases are magical and amazing pieces of software. If you don’t agree with me, please let these awesome resources change your mind. In addition to being magical and amazing, they’re also mysterious and complex, using advanced data structures and algorithms to store data efficiently and handle concurrent access. I use databases all the time but am pretty much oblivious to how they work under the hood. Let’s fix that knowledge deficiency by getting down and dirty with a foundational concept of modern databases: transactions.
This is the first part of a multi-part series of articles. Stay tuned for Part 2, in which we’ll begin building a simple transactional database from scratch! Let’s get started.
What the hell are ACID transactions?
You might have heard that ACID in database-land stands for Atomicity, Consistency, Isolation, and Durability. Those terms are fine and dandy, but what do they actually mean? ACID refers to properties of database transactions, which are indivisible units of work that a database executes. We’ll be going over transactions, each of the ACID properties, and why they’re important.
What happens when you don’t have ACID
To better understand what transactions are, we need to first understand the problems they solve. Consider this Go function that withdraws money from a bank account. It does not use database transactions to accomplish this.
// withdraw decrements account balance by a specified amount.
func withdraw(account string, amount int) error {
balance, err := db.Get(account)
if err != nil {
return fmt.Errorf("account %v not found: %w", account, err)
}
balance -= amount
// Enforce constraint that balances cannot be negative.
if balance < 0 {
return fmt.Errorf("balance of %v for account %v is below $0",
balance, account)
}
return db.Put(account, balance) // return error if Put() fails
}
This code works perfectly if only one thread is accessing the database at a time. However, we live in a world where concurrency abounds. Applications must handle requests concurrently to serve multiple users at the same time. What happens if we call withdraw() from two threads (or goroutines) at the same time?
func main() {
// Account "brian" initially has $100.
go withdraw("brian", 70)
withdraw("brian", 80)
// Now "brian" has $20???
}
This code may result in a database access pattern that looks like this:
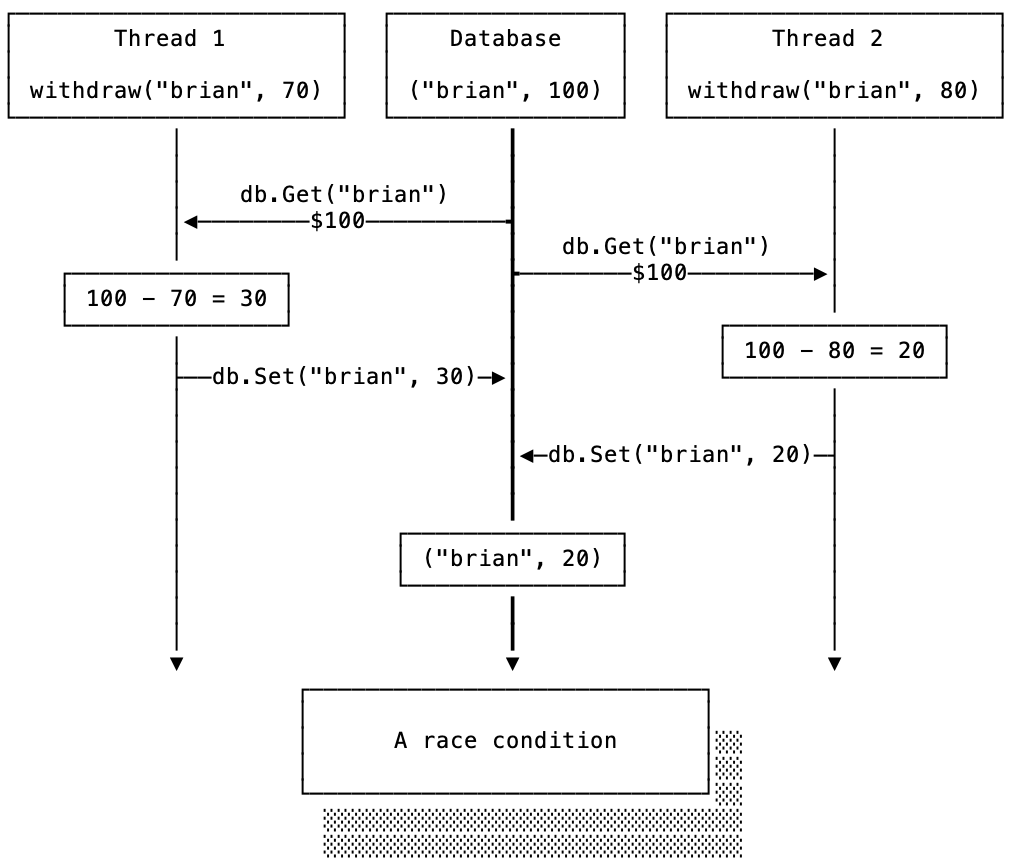
In this example, Thread_1 and Thread_2 withdraw a total of $150 from brian’s original account balance of $100. Both calls to withdraw() succeed and the final state of the database says that brian has $20. Why?
Thread_1 and Thread_2 both read the original balance of brian and then Thread_1 commits its updated balance. Soon after, Thread_2 commits its own updated balance. Since Thread_1 and Thread_2 are unaware of each other’s actions, they both commit and the results of Thread_1 are overwritten by Thread_2. In fancier, more technical terms, this is called a lost update and is just one type of write anomaly1 that you are vulnerable to if you don’t use transactions.
As soon as we introduce concurrency into our application, it becomes much harder to reason about database accesses. Each read or write to the database from different threads can be interleaved in any order, nondeterministically2. The diagram above specifies just one of many ways those operations could have executed. If we’re lucky, both threads could run and work as expected, with one of the calls to withdraw() returning an error. This nondeterminism is what makes concurrency bugs so insidious and hard to catch.
How transactions help
Transactions solve this by being atomic. They allow you to execute multiple operations together, as a single unit of work. Transactions guarantee that their operations will never be interleaved with those of another transaction that might conflict with it.
Here’s what a transactional version of our withdraw() function might look like3:
// withdraw decrements account balance by a specified amount.
func withdraw(account string, amount int) error {
// Execute database transaction to atomically withdraw from account.
return db.Update(func (txn *db.Txn) error {
balance, err := txn.Get(account)
if err != nil {
return fmt.Errorf("account %v not found: %w", account, err)
}
balance -= amount
// Constraint: can't have a negative balance!
if balance < 0 {
return fmt.Errorf("balance of %v for account %v is below $0",
balance, account)
}
return txn.Put(account, balance) // return error if Put() fails
})
}
If we use transactions, withdraw()’s Get and Put operations will always execute together. Thus, the prior example of conflicting calls to withdraw() will always result in one of the calls failing. In other words, using transactions makes lost updates impossible! Hooray!
In addition to atomicity, transactions offer other guarantees like consistency, isolation, and durability. Here are their definitions:
- Atomicity – all steps of a transaction will finish successfully or none of them will. There will never be an “in-between” state that other transactions can see.
- Consistency – a transaction can only cause the database to move from one valid state to another valid state. All database invariants and constraints defined by the user must be honored at all times. Consistency guarantees that databases cannot be corrupted by illegal transactions4.
- Isolation – transactions can run without interference from any other concurrently executing transactions. The isolation level of a database controls both when and what changes to the database become visible to transactions. Isolation is heavily influenced by the database’s mechanism for concurrency control.
- Durability – when a transaction commits, it will immediately write changes to persistent storage. If the database or machine crashes, the database can recover all committed changes from disk.
All of these properties work together to help ensure that modern databases maintain data integrity.
Conclusion
Yay! We learned a lot about ACID transactions and the types of bugs that they help prevent. That’s pretty good for one blog post, if you ask for my totally unbiased opinion ![]() .
.
In Part 2 of this series, we’ll start building lsdb, an in-memory key-value store that supports ACID transactions. We’ll learn how to implement transactions in code and explore multiversion concurrency control, the concurrency control mechanism used in Postgres. Stay tuned!
References
- Database Internals by Alex Petrov
- Designing Data Intensive Applications by Martin Kleppmann
-
Other read and write anomalies that can occur include dirty reads, nonrepeatable reads, phantom reads, dirty writes, and write skew. You should look them up if you’re interested in them but they won’t be covered here for the sake of conciseness. ↩
-
The order is nondeterministic because thread execution is dictated by the operating system’s scheduler. If multiple threads are performing reads/writes at the same time, the order in which they execute is largely opaque to and uncontrollable by applications unless some sort of synchronization method is used. We’ll be covering concurrency control methods in Part 2. ↩
-
This syntax is inspired by BadgerDB, a database written in Go that supports ACID transactions. ↩
-
Note that consistency does not guarantee the correctness of the transactions that you write. Constraints here refer to things like
UNIQUEorNOT NULLin Postgres, not application logic constraints. ↩